Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
How to stop Google crawling after 301 redirect?
-
I have removed all pages from my old website and set 301 redirect to new website. But, I have verified old website with Google webmaster tools' HTML verification file which enable me to track all data and existence of pages in Google search for my old website. I was assumed that, Google will stop crawling and DE-indexed all pages after 301 redirect. Because, I have set 301 redirect before 3 months.
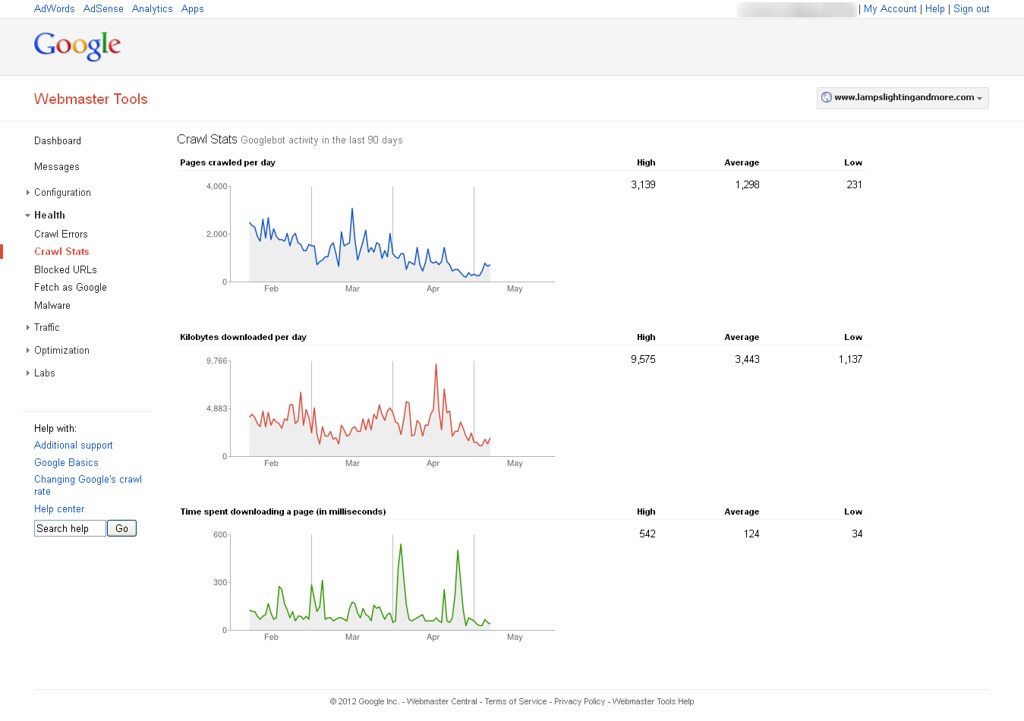
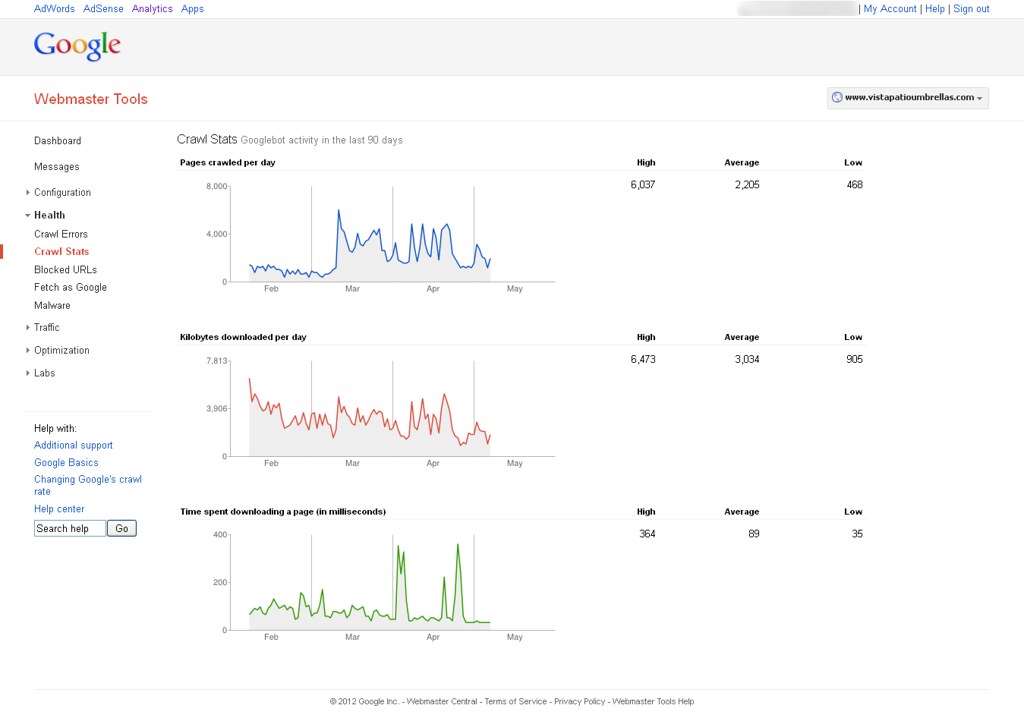
Now, I'm able to see Google bot activity on my website with help of Google webmaster tools. You can find out attachment to know more about it. How can it possible & How Google can crawl removed pages?
You can see following image to know more about it.
&
-
Google is most likely following links on other sites pointing to your old site and then 301'ing to the new site so you're seeing activity in WMT
looking here is still see two pages in the index:
you can go in and remove the site in WMT using the remove URL tool and see if that stops activity in that old WMT account. Crawling or not crawling, reporting or not reporting, there is not an issue here though - the 301's appear to be properly set up.
{kind=link}
{kind=link}
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Does Google Index URLs that are always 302 redirected
Hello community Due to the architecture of our site, we have a bunch of URLs that are 302 redirected to the same URL plus a query string appended to it. For example: www.example.com/hello.html is 302 redirected to www.example.com/hello.html?___store=abc The www.example.com/hello.html?___store=abc page also has a link canonical tag to www.example.com/hello.html In the above example, can www.example.com/hello.html every be Indexed, by google as I assume the googlebot will always be redirected to www.example.com/hello.html?___store=abc and will never see www.example.com/hello.html ? Thanks in advance for the help!
Intermediate & Advanced SEO | | EcommRulz0 -

Changing URL structure of date-structured blog with 301 redirects
Howdy Moz, We've recently bought a new domain and we're looking to change over to it. We're also wanting to change our permalink structure. Right now, it's a WordPress site that uses the post date in the URL. As an example: http://blog.mydomain.com/2015/01/09/my-blog-post/ We'd like to use mod_rewrite to change this using regular expressions, to: http://newdomain.com/blog/my-blog-post/ Would this be an appropriate solution? RedirectMatch 301 /./././(.) /blog/$1
Intermediate & Advanced SEO | | IanOBrien0 -

Can an incorrect 301 redirect or .htaccess code cause 500 errors?
Google Webmaster Tools is showing the following message: _Googlebot couldn't access the contents of this URL because the server had an internal error when trying to process the request. These errors tend to be with the server itself, not with the request. _ Before I contact the person who manages the server and hosting (essentially asking if the error is on his end) is there a chance I could have created an issue with an incorrect 301 redirect or other code added to .htaccess incorrectly? Here is the 301 redirect code I am using in .htaccess: RewriteEngine On RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /([^/.]+/)*(index.html|default.asp)\ HTTP/ RewriteRule ^(([^/.]+/)*)(index|default) http://www.example.com/$1 [R=301,L] RewriteCond %{HTTP_HOST} !^(www.example.com)?$ [NC] RewriteRule (.*) http://www.example.com/$1 [R=301,L] Could adding the following code after that in the .htaccess potentially cause any issues? BEGIN EXPIRES <ifmodule mod_expires.c="">ExpiresActive On
Intermediate & Advanced SEO | | kimmiedawn
ExpiresDefault "access plus 10 days"
ExpiresByType text/css "access plus 1 week"
ExpiresByType text/plain "access plus 1 month"
ExpiresByType image/gif "access plus 1 month"
ExpiresByType image/png "access plus 1 month"
ExpiresByType image/jpeg "access plus 1 month"
ExpiresByType application/x-javascript "access plus 1 month"
ExpiresByType application/javascript "access plus 1 week"
ExpiresByType application/x-icon "access plus 1 year"</ifmodule> END EXPIRES (Edit) I'd like to add that there is a Wordpress blog on the site too at www.example.com/blog with the following code in it's .htaccess: BEGIN WordPress <ifmodule mod_rewrite.c="">RewriteEngine On
RewriteBase /blog/
RewriteRule ^index.php$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /blog/index.php [L]</ifmodule> END WordPress Thanks0 -

Remove URLs that 301 Redirect from Google's Index
I'm working with a client who has 301 redirected thousands of URLs from their primary subdomain to a new subdomain (these are unimportant pages with regards to link equity). These URLs are still appearing in Google's results under the primary domain, rather than the new subdomain. This is problematic because it's creating an artificial index bloat issue. These URLs make up over 90% of the URLs indexed. My experience has been that URLs that have been 301 redirected are removed from the index over time and replaced by the new destination URL. But it has been several months, close to a year even, and they're still in the index. Any recommendations on how to speed up the process of removing the 301 redirected URLs from Google's index? Will Google, or any search engine for that matter, process a noindex meta tag if the URL's been redirected?
Intermediate & Advanced SEO | | trung.ngo0 -

Any way to find which domains are 301 redirected to competitors' websites?
By looking at the work from an SEO collegue it became clear that his weak linkbuilding graph probably is not the cause for his good rankings for a pretty competitive keyword. (also no social mentions where found) I was wondering what it could be, site structure and other on page optimization factors seems to be ok and I don't think there will be exceptionally good or bad user behavior... Finally I looked at the competitors and found that they have more links, better content en better design, so I got a little stuck. The only reason I can think of is that he is doing 301 redirects (or is rel=canonical tags). Is there a way to trace these redirects back to the source in order to include this important variable in your competitor research? thnx
Intermediate & Advanced SEO | | djingel10 -

How to prevent Google from crawling our product filter?
Hi All, We have a crawler problem on one of our sites www.sneakerskoopjeonline.nl. On this site, visitors can specify criteria to filter available products. These filters are passed as http/get arguments. The number of possible filter urls is virtually limitless. In order to prevent duplicate content, or an insane amount of pages in the search indices, our software automatically adds noindex, nofollow and noarchive directives to these filter result pages. However, we’re unable to explain to crawlers (Google in particular) to ignore these urls. We’ve already changed the on page filter html to javascript, hoping this would cause the crawler to ignore it. However, it seems that Googlebot executes the javascript and crawls the generated urls anyway. What can we do to prevent Google from crawling all the filter options? Thanks in advance for the help. Kind regards, Gerwin
Intermediate & Advanced SEO | | footsteps0