Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
Blocking URL's with specific parameters from Googlebot
-
Hi,
I've discovered that Googlebot's are voting on products listed on our website and as a result are creating negative ratings by placing votes from 1 to 5 for every product. The voting function is handled using Javascript, as shown below, and the script prevents multiple votes so most products end up with a vote of 1, which translates to "poor".
How do I go about using robots.txt to block a URL with specific parameters only? I'm worried that I might end up blocking the whole product listing, which would result in de-listing from Google and the loss of many highly ranked pages.
DON'T want to block:
http://www.mysite.com/product.php?productid=1234
WANT to block:
http://www.mysite.com/product.php?mode=vote&productid=1234&vote=2
Javacript button code:
onclick="javascript: document.voteform.submit();"
Thanks in advance for any advice given.
Regards,
Asim -
Good to hear, I am glad you perservered
-
Tried them all now and all come back with "Success"... May be I'll post in the WMT Forum and see if anyone can shed light on this problem. Thanks for your help Alan, it's much appreciated.
-
Yes correct, did you try the other formats?
-
Tried "Fetch as Googlebot" in Diagnostics and it came back as "Success" so I guess the robots.txt directive is not working. I'm assuming it should have reported a failure message when attempting to fetch a URL containing "?mode=vote".
-
Wrong place, go to diagnostics, then look for fetch as googlebot
-
I added "Disallow: /mode=vote" to the robots.txt file and also manually entered it on Crawler Access page, then clicked "Test" and no errors were reported. The WMT page states that robots.txt was last downloaded 16 hours ago so I'll wait until it picks the file up again and then check for any errors. Hopefully that will do trick
")
-
Try this in robots.txt, I did not think that Google allows wild cards but i just read that they do.
Disallow: /*mode=vote*orDisallow: /*mode=voteorDisallow: /*modeThen try in Google WMT to read with googlebot to see if it works.The first in the list seems right to me, but I have seen others do it the other ways. -
Thanks for the reply. The site was developed using PHP, mySQL and Javascript. I was hoping there was a way to do it without getting programmers involved...
-
dont think you are going to do it in robots.txt, rather do a 301 from mode=vote to non mode vote.
If you dont know how to put this into practise, tell me what your site is built with, if it is ASP.NET, i will show you how to impliment, if not someone else should be able to help.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Category URL Pagination where URLs don't change between pages
Hello, I am working on an e-commerce site where there are categories with multiple pages. In order to avoid pagination issues I was thinking of using rel=next and rel=prev and cannonical tags. I noticed a site where the URL doesn't change between pages, so whether you're on page 1,2, or 3 of the same category, the URL doesn't change. Would this be a cleaner way of dealing with pagination?
Technical SEO | | whiteonlySEO0 -

Why Can't Googlebot Fetch Its Own Map on Our Site?
I created a custom map using google maps creator and I embedded it on our site. However, when I ran the fetch and render through Search Console, it said it was blocked by our robots.txt file. I read in the Search Console Help section that: 'For resources blocked by robots.txt files that you don't own, reach out to the resource site owners and ask them to unblock those resources to Googlebot." I did not setup our robtos.txt file. However, I can't imagine it would be setup to block google from crawling a map. i will look into that, but before I go messing with it (since I'm not familiar with it) does google automatically block their maps from their own googlebot? Has anyone encountered this before? Here is what the robot.txt file says in Search Console: User-agent: * Allow: /maps/api/js? Allow: /maps/api/js/DirectionsService.Route Allow: /maps/api/js/DistanceMatrixService.GetDistanceMatrix Allow: /maps/api/js/ElevationService.GetElevationForLine Allow: /maps/api/js/GeocodeService.Search Allow: /maps/api/js/KmlOverlayService.GetFeature Allow: /maps/api/js/KmlOverlayService.GetOverlays Allow: /maps/api/js/LayersService.GetFeature Disallow: / Any assistance would be greatly appreciated. Thanks, Ruben
Technical SEO | | KempRugeLawGroup1 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
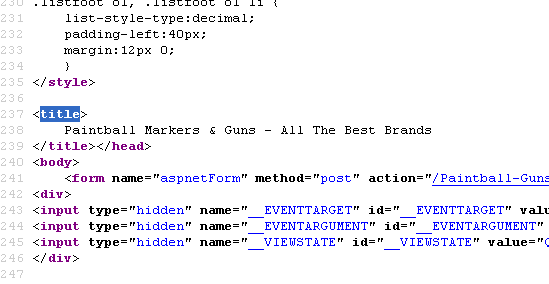 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

Blocked URL parameters can still be crawled and indexed by google?
Hy guys, I have two questions and one might be a dumb question but there it goes. I just want to be sure that I understand: IF I tell webmaster tools to ignore an URL Parameter, will google still index and rank my url? IS it ok if I don't append in the url structure the brand filter?, will I still rank for that brand? Thanks, PS: ok 3 questions :)...
Technical SEO | | catalinmoraru0 -

Correct linking to the /index of a site and subfolders: what's the best practice? link to: domain.com/ or domain.com/index.html ?
Dear all, starting with my .htaccess file: RewriteEngine On
Technical SEO | | inlinear
RewriteCond %{HTTP_HOST} ^www.inlinear.com$ [NC]
RewriteRule ^(.*)$ http://inlinear.com/$1 [R=301,L] RewriteCond %{THE_REQUEST} ^./index.html
RewriteRule ^(.)index.html$ http://inlinear.com/ [R=301,L] 1. I redirect all URL-requests with www. to the non www-version...
2. all requests with "index.html" will be redirected to "domain.com/" My questions are: A) When linking from a page to my frontpage (home) the best practice is?: "http://domain.com/" the best and NOT: "http://domain.com/index.php" B) When linking to the index of a subfolder "http://domain.com/products/index.php" I should link also to: "http://domain.com/products/" and not put also the index.php..., right? C) When I define the canonical ULR, should I also define it just: "http://domain.com/products/" or in this case I should link to the definite file: "http://domain.com/products**/index.php**" Is A) B) the best practice? and C) ? Thanks for all replies! 🙂
Holger0 -
Mobile URL parameter (Redirection to desktop)
Hello, We have a parallel mobile website and recently we implemented a link pointing to the desktop website. This redirect is happening via a javascript code and results in a url followed by this paramenter: ?m=off Example:
Technical SEO | | echo1
http://www.m.website.com redirects to:
http://www.website.com/?m=off Questions: Will the "http://www.website.com/?m=off" be considered duplicate content with "http://www.website.com" since they both return the same content? Is there any possibility that Google will take into consideration the url ending in "/?m=off"? How should we treat this new url? The webmaster tools URL parameter configuration at the moment isn't experiencing problems but should we submit the parameter anyway in order not to be indexed or should we wait first and see the error response? In case we should submit this for removal... what's the best way to do it? Like this? Parameter: ?m=off Does this parameter change page content seen by the user? - doesn't affect page content Any help is much appreciated.
Thank you!0 -
Are Collapsible DIV's SEO-Friendly?
When I have a long article about a single topic with sub-topics I can make it user friendlier when I limit the text and hide text just showing the next headlines, by using expandable-collapsible div's. My doubt is if Google is really able to read onclick textlinks (with javaScript) or if it could be "seen" as hidden text? I think I read in the SEOmoz Users Guide, that all javaScript "manipulated" contend will not be crawled. So from SEOmoz's Point of View I should better make use of old school named anchors and a side-navigation to jump to the sub-topics? (I had a similar question in my post before, but I did not use the perfect terms to describe what I really wanted. Also my text is not too long (<1000 Words) that I should use pagination with rel="next" and rel="prev" attributes.) THANKS for every answer 🙂
Technical SEO | | inlinear0 -

Ecommerce website: Product page setup & SKU's
I manage an E-commerce website and we are looking to make some changes to our product pages to try and optimise them for search purposes and to try and improve the customer buying experience. This is where my head starts to hurt! Now, let's say I am selling a T shirt that comes in 4 sizes and 6 different colours. At the moment my website would have 24 products, each with pretty much the same content (maybe differing references to the colour & size). My idea is to change this and have 1 main product page for the T-shirt, but to have 24 product SKU's/variations that exist to give the exact product details. Some different ways I have been considering to do this: a) have drop-down fields on the product page that ask the customer to select their Tshirt size and colour. The image & price then changes on the page. b) All product 24 product SKUs sre listed under the main product with the 'Add to Cart' open next to each one. Each one would be clickable so a page it its own right. Would I need to set up a canonical links for each SKU that point to the top level product page? I'm obviously looking to minimise duplicate content but Im not exactly sure on how to set this up - its a big decision so I need to be 100% clear before signing off on anything. . Any other tips on how to do this or examples of good e-commerce websites that use product SKus well? Kind regards Tom
Technical SEO | | DHS_SH0